ARM Cortex-m Fault Exceptions 文档学习
为了尽早发现问题,所有 Cortex-M 处理器都内建了故障异常机制。当检测到故障时,相应的故障异常会被触发,并执行对应的异常处理程序。本文档介绍了故障异常的使用方法,列出了系统控制块(System Control Block,SCB)中用于控制故障异常或提供故障原因信息的外设寄存器。文中还通过软件示例展示了故障异常在程序调试过程中或在应用软件中进行错误恢复时的使用方式。
1 故障异常(Fault exception)处理程序
故障异常用于捕获非法的内存访问和非法的程序行为。以下几种情况可由故障异常处理程序检测:
HardFault(硬故障):这是默认的异常类型,通常在异常处理过程中发生错误,或当某个异常无法由其他异常机制处理时触发。
MemManage(内存管理故障):用于检测对由内存管理单元(MPU)定义的区域的非法访问。例如,在仅具有读/写权限的内存区域执行代码。
BusFault(总线故障):用于检测指令获取、数据读写、中断向量获取以及中断时寄存器堆栈操作(保存/恢复)中的内存访问错误。
UsageFault(使用故障):用于检测未定义指令的执行、非对齐的多数据加载/存储访问。当启用后,还可检测除以零和其他非对齐的内存访问。
2 故障异常(Fault exception)的编号与优先级
每个异常都具有一个对应的异常编号和优先级编号。为了简化软件层的处理,CMSIS(Cortex Microcontroller Software Interface Standard)仅使用 IRQ 编号,因此对于非中断类的异常使用负值表示。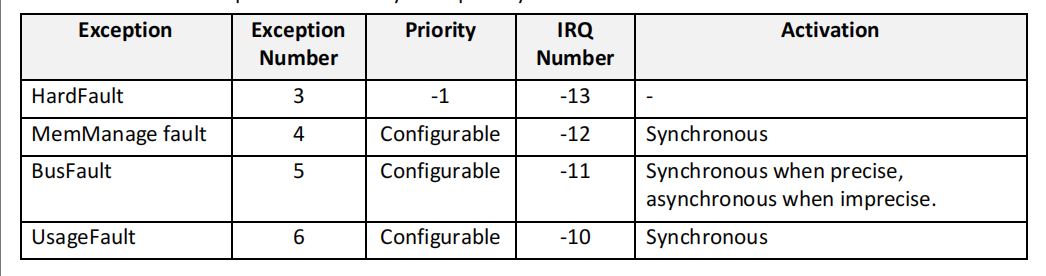
HardFault 异常始终处于启用状态,并具有固定优先级(高于其他中断和异常,但低于不可屏蔽中断 NMI)。因此,在某个故障异常被禁用,或在执行某个故障异常处理程序期间发生新的故障时,HardFault 异常将被触发执行。
其他故障异常(如 MemManage、BusFault 和 UsageFault)具有可编程的优先级。在系统复位后,这些异常默认处于禁用状态,可以通过系统或应用软件中的系统控制块(System Control Block,SCB)寄存器进行启用。
3 优先级提升(Priority Escalation)
通常,异常的优先级与异常屏蔽寄存器的值共同决定处理器是否进入故障处理程序,以及一个故障处理程序是否可以抢占另一个故障处理程序。
在某些情况下,具有可配置优先级的故障会被当作 HardFault(硬故障)处理。这种情况称为优先级提升,即故障被“提升”为 HardFault。以下情况会触发优先级提升(“优先级提升”,是新发生的故障被“强制”转为 HardFault 来处理。):
- 故障处理程序在处理某类故障时再次引发相同类型的故障。由于处理程序无法抢占自身(其优先级与当前处理级别相同),因此会被提升为 HardFault。
- 故障处理程序引发了一个优先级相同或更低的故障。由于新故障的处理程序无法抢占当前正在执行的处理程序,因此会被提升为 HardFault。
- 异常处理程序引发了一个优先级相同或更低的故障。同样由于抢占失败,故障会被提升为 HardFault。
- 发生故障时,其对应的处理程序未启用。此时系统无法进入该处理程序,只能转而执行 HardFault。
如果在进入 BusFault 处理程序时,堆栈压入操作(stack push)过程中发生 BusFault,该故障不会被提升为 HardFault。这意味着即使堆栈损坏导致故障,处理器仍会执行 BusFault 处理程序,尽管堆栈内容可能已损坏。
注意事项:
- 只有 复位(Reset) 和 不可屏蔽中断(NMI) 可以抢占固定优先级的 HardFault。
- HardFault 可以抢占除 Reset、NMI 和另一个 HardFault 之外的任何异常。
4 同步与异步 BusFault(总线故障)
BusFault 可细分为两类:同步总线故障与异步总线故障。故障处理程序可通过 BFSR(BusFault Status Register,总线故障状态寄存器) 来判断故障类型:
PRECISERR 表示同步(精确)故障;
IMPRECISERR 表示异步(不精确)故障。
同步总线故障(Synchronous BusFault / Precise BusFault)
- 指在总线传输完成后立即发生的异常。
- 这种故障是可定位的,因为它与当前指令直接相关。
- 如果在 NMI 或 HardFault 处理程序内部发生同步 BusFault,可能会导致系统锁死(lockup)。
- 缓存维护操作(如清除或失效)也可能触发同步 BusFault。
- 调试访问(如调试器的加载或存储操作)也可能触发 BusFault,这类访问是同步的,仅对调试接口可见。
异步总线故障(Asynchronous BusFault / Imprecise BusFault)
- 通常由于处理器设计中的写缓冲机制引起。
- 处理器流水线会继续执行后续指令,而在稍后才观察到总线错误响应。
- 如果此时有更高优先级的中断到达,异步 BusFault 会被挂起(pended),先执行该中断处理程序,之后再处理 BusFault。
- 如果 BusFault 处理程序未启用,则会挂起一个 HardFault 异常来代替处理。
- 异步 BusFault 引发的 HardFault 不会导致系统锁死。
- 异步故障通常是不可恢复的,因为无法确定是哪条指令导致了错误。
5 故障异常的控制寄存器
系统控制块(System Control Block,SCB)提供了系统实现信息和系统控制功能,包括系统异常的配置、控制与状态报告。其中有几个关键寄存器用于控制故障异常:
CCR(Configuration and Control Register,配置与控制寄存器) 控制 UsageFault 异常的行为,特别是是否启用对“除以零”和“非对齐内存访问”的检测。
DIV_0_TRP:当处理器执行 SDIV 或 UDIV 指令且除数为 0 时,是否触发 UsageFault 异常:、
- 0:不触发异常,除以零的结果返回为 0;
- 1:触发异常,进入 UsageFault 处理程序。
UNALIGN_TRP:当进行非对齐地址的内存访问时,是否触发 UsageFault 异常:
- 0:不触发异常,允许非对齐的半字和字访问;
- 1:触发异常,非对齐访问将引发 UsageFault。
- 注意:即使 UNALIGN_TRP 设置为 0,使用 LDM、STM、LDRD 和 STRD 指令进行非对齐访问仍会触发 UsageFault。
SHP(System Handler Priority Registers,系统管理程序优先级寄存器) 用于设置系统异常(如 MemManage、BusFault、UsageFault、SVCall 等)的优先级。 每个异常都有对应的优先级字段,优先级值越小,优先级越高。以下索引对应故障异常的优先级设置:
- SHP[0]:内存管理故障(Memory Management Fault)的优先级;
- SHP[1]:总线故障(BusFault)的优先级;
- SHP[2]:使用故障(UsageFault)的优先级。
使用 CMSIS 提供的函数设置优先级示例:
1 | NVIC_SetPriority(MemoryManagement_IRQn, 0x0F); // 设置 MemManage 优先级为最低 |
SHCSR(System Handler Control and State Register,系统管理程序控制与状态寄存器) 用于启用系统异常处理器,并报告某些异常的挂起状态。 包括 MEMFAULTENA、BUSFAULTENA、USGFAULTENA 等位,用于启用对应的异常处理器。 还包含 SVCALLPENDED、BUSFAULTPENDED 等位,用于指示异常是否处于挂起状态。
启用所有故障异常的示例代码:
1 | SCB->SHCSR |= SCB_SHCSR_USGFAULTENA_Msk |
6 故障异常的状态寄存器与地址寄存器
下表列出了各类故障异常对应的状态寄存器和地址寄存器,并标明了每个寄存器在内存中的地址:
| 异常类型 | 状态寄存器 | 地址寄存器 | 寄存器地址 | 描述说明 |
|---|---|---|---|---|
| HardFault | HFSR | — | 0xE000ED2C |
硬故障状态寄存器(HardFault Status Register) |
| MemManage | MMFSR | MMFAR | 0xE000ED28(状态)0xE000ED34(地址) |
内存管理故障状态寄存器与地址寄存器 |
| BusFault | BFSR | BFAR | 0xE000ED29(状态)0xE000ED38(地址) |
总线故障状态寄存器与地址寄存器 |
| UsageFault | UFSR | — | 0xE000ED2A |
使用故障状态寄存器 |
| AFSR | — | 0xE000ED3C |
辅助故障状态寄存器,内容由实现定义 | |
| ABFSR | — | 0xE000ED3C |
辅助总线故障状态寄存器,仅适用于 Cortex-M7 |
6.1 HardFault 状态寄存器(HFSR)
HardFault 状态寄存器用于指示处理器指令的错误使用情况,包含以下状态位:
- VECTTBL:表示在异常处理过程中读取向量表时发生了总线故障(BusFault):
- 0:读取向量表时未发生总线故障;
- 1:读取向量表时发生了总线故障。
- 当该位被置位时,异常返回时堆栈中的 PC 值指向的是被异常抢占的指令位置(这个被压入堆栈的PC值一般不指向导致总线错误的那条指令(比如一条错误的内存访问指令)。相反,它指向的是被异常抢占的那个任务的指令流中的某条指令)。此类错误始终被视为 HardFault。
- FORCED:表示强制性 HardFault,由无法处理的可配置优先级故障升级而来(可能由于优先级问题或异常处理器未启用):
- 0:未发生强制性 HardFault;
- 1:发生了强制性 HardFault。
- 当该位被置位时,HardFault 处理程序应读取其他故障状态寄存器,以确定故障的具体原因。
- DEBUGEVT:保留用于调试用途。在向该寄存器写入时,必须将此位写为 0,否则行为不可预测。
6.2 可配置故障状态寄存器 (CFSR - Configurable Fault Status Register)
CFSR 寄存器可分为三个状态寄存器:用法故障 (Usage Fault)、总线故障 (Bus Fault) 和 内存管理故障 (MemManage Fault) 状态寄存器。
6.2.1 内存管理状态寄存器 (MMFSR - MemManage Status Register)
内存管理故障状态寄存器 (MMFSR) 指示由 内存保护单元 (MPU - Memory Protection Unit) 检测到的内存访问违规。该寄存器仅允许特权访问。非特权访问将生成总线故障 (BusFault)。
MMFSR 包含以下状态位: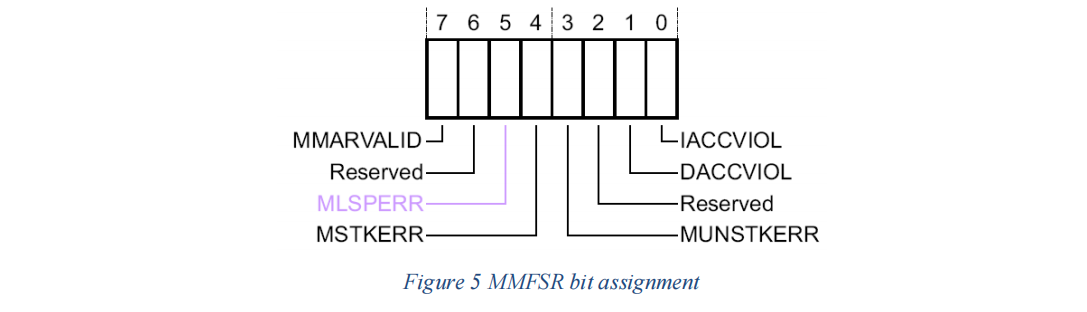
IACCVIOL (指令访问违规标志):
- 0 = 无指令访问违规故障
- 1 = 处理器尝试从不允许执行的位置获取指令。
- 为异常返回而压入堆栈的 PC 值指向引发故障的指令。处理器未将故障地址写入 MMFAR。
此故障条件发生在任何尝试从 XN (eXecute Never, 永不执行) 区域获取指令的时候,即使 MPU 被禁用或不存在也会发生。
潜在原因:
a) 跳转(Branch)到 MPU 中未定义或定义为不可执行的区域。
b) 由于栈内容损坏而导致无效返回。
c) 异常向量表中的条目不正确。
DACCVIOL (数据访问违规标志):
- 0 = 无数据访问违规故障
- 1 = 处理器尝试在不允许该操作(加载或存储)的位置进行数据访问。
- 为异常返回而压入堆栈的 PC 值指向引发故障的指令。处理器已将尝试访问的数据地址加载到了 MMFAR 中。
MUNSTKERR (异常返回出栈过程中发生的内存管理故障):
- 0 = 无出栈故障
- 1 = 为异常返回而进行的出栈操作导致了一次或多次访问违规。
- 此故障与处理程序是链式(chained) 的,这意味着原始的返回栈仍然存在。处理器未从失败返回中调整 SP(栈指针),也未执行新的上下文保存。处理器未将故障地址写入 MMFAR。
潜在原因:
a) 栈指针 (SP) 已损坏。
b) 异常处理程序执行期间,用于栈的 MPU 区域发生了更改。
MSTKERR (异常入口压栈过程中发生的内存管理故障):
- 0 = 无压栈故障
- 1 = 为异常入口而进行的压栈操作导致了一次或多次访问违规。
- SP 已被调整,但栈上上下文区域中的值可能是错误的。处理器未将故障地址写入 MMFAR。
潜在原因:
a) 栈指针 (SP) 已损坏或未初始化。
b) 栈触及到了 MPU 未定义为读/写内存的区域。
MLSPERR (浮点惰性状态保存期间的内存管理故障) (仅限带 FPU 的 Cortex-M4):
- 0 = 浮点惰性状态保存期间未发生故障
- 1 = 浮点惰性状态保存期间发生故障
- PS:惰性保存:发生异常时,处理器暂时不保存浮点寄存器,它只是标记一个“FPU状态需要保存”的标志。只有当异常处理程序内部第一次尝试执行浮点指令时,处理器才会检测到这个标志,并在此时真正执行保存所有浮点寄存器的操作。
浮点惰性状态保存期间的内存管理故障:在惰性保存机制被触发的那个时间点(即异常处理程序中第一次执行浮点指令,处理器需要将S0-S31等FPU寄存器保存到堆栈时),此次保存操作本身(一次对堆栈的大规模写操作)违反了MPU的规则,从而触发了内存管理故障(MemManage Fault)。
MMARVALID (内存管理故障地址寄存器 (MMFAR) 有效标志):
- 0 = SCB->MMFAR 中的值不是有效的故障地址
- 1 = SCB->MMFAR 中持有有效的故障地址。
如果发生内存管理故障,并因优先级原因升级 (escalated) 为 HardFault,则 HardFault 处理程序必须将此位清零 (0)。这样可以避免在返回到一个栈上的活动 MemManage 故障处理程序时出现问题,因为该处理程序的 SCB->MMFAR 值可能已被覆盖。
6.2.2 总线故障状态寄存器 (BFSR - BusFault Status Register)
总线故障状态寄存器显示了由指令预取和数据访问引起的总线错误状态,并指示在总线操作期间检测到的存储器访问故障。该寄存器仅允许特权访问。非特权访问将生成总线故障。
BFSR 包含以下状态位: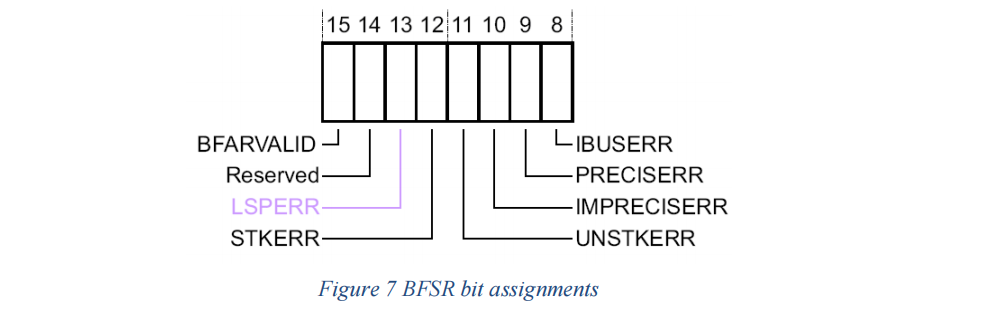
IBUSERR (指令总线错误):
- 0 = 无指令总线错误
- 1 = 发生指令总线错误。
- 处理器在预取指令时检测到指令总线错误,但仅当它尝试执行该故障指令时才会将 IBUSERR 标志置 1。当处理器置位此位时,不会将故障地址写入 BFAR。
潜在原因:
a) 跳转到无效内存区域,例如由不正确的函数指针引起。
b) 由于栈指针或栈内容损坏而导致无效返回。
c) 异常向量表中的条目不正确。
PRECISERR (精确数据总线错误):
- 0 = 无精确数据总线错误
- 1 = 已发生数据总线错误,且为异常返回而压入堆栈的 PC 值精确指向了引发故障的指令。
当处理器置位此位时,它会将故障地址写入 BFAR。这对于调试至关重要。
IMPRECISERR (不精确数据总线错误):
- 0 = 无不精确数据总线错误
- 1 = 已发生数据总线错误,但栈帧中的返回地址与引发错误的指令无关。
- 当处理器置位此位时,它不会将故障地址写入 BFAR。这是一种异步故障。因此,如果在当前进程的优先级高于总线故障优先级时检测到它,则总线故障会保持挂起 (pending) 状态,仅当处理器从所有更高优先级进程返回后才会变为活动 (active) 状态。如果在处理器进入不精确总线故障的处理程序之前发生了精确故障,则处理程序会检测到 IMPRECISERR 置 1 并且某个精确故障状态位也置 1。
UNSTKERR (异常返回出栈过程中的总线故障):
- 0 = 无出栈故障
- 1 = 为异常返回而进行的出栈操作导致了一次或多次总线故障。
- 此故障与处理程序是链式(chained) 的。这意味着当处理器置位此位时,原始的返回栈仍然存在。处理器不会从失败返回中调整 SP(栈指针),不会执行新的上下文保存,也不会将故障地址写入 BFAR。
STKERR (异常入口压栈过程中的总线故障):
- 0 = 无压栈故障
- 1 = 为异常入口而进行的压栈操作导致了一次或多次总线故障。
当处理器置位此位时,SP 已被调整,但栈上上下文区域中的值可能是错误的。处理器不会将故障地址写入 BFAR。
潜在原因:
a) 栈指针 (SP) 已损坏或未初始化。
b) 栈触及到了未定义的存储器区域。
LSPERR (浮点惰性状态保存期间的总线故障) (仅在存在 FPU 时):
- 0 = 浮点惰性状态保存期间未发生故障
- 1 = 浮点惰性状态保存期间发生故障
(其机制与 MemManage 故障中的 MLSPERR 类似,但触发的是总线错误而非内存保护错误)。
BFARVALID (总线故障地址寄存器 (BFAR) 有效标志):
- 0 = BFAR 中的值不是有效的故障地址
- 1 = BFAR 中持有有效的故障地址。
处理器在地址已知的总线故障发生后置位此位。其他故障(例如随后发生的 MemManage 故障)可以将此位清零。如果发生总线故障并因优先级原因升级为 HardFault,则 HardFault 处理程序必须将此位清零 (0)。这样可以避免在返回到一个栈上的活动 BusFault 故障处理程序时出现问题,因为该处理程序的 BFAR 值可能已被覆盖。
6.2.3 用法故障状态寄存器 (UFSR - UsageFault Status Register)
用法故障状态寄存器 (UFSR) 包含了某些指令执行故障和数据访问故障的状态。该寄存器仅允许特权访问。非特权访问将生成总线故障 (BusFault)。
该寄存器包含以下定义位: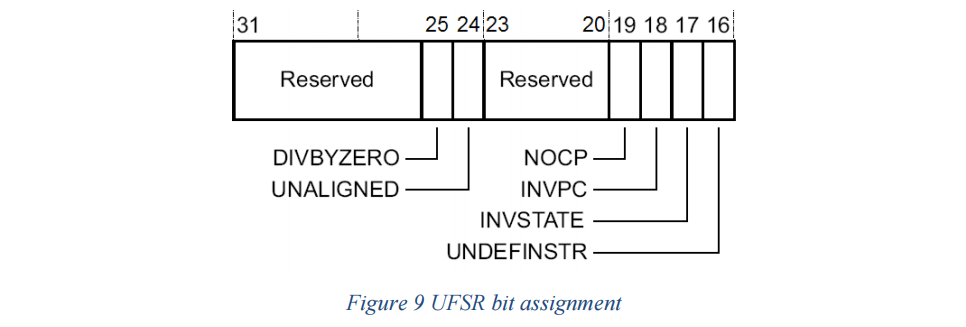
UNDEFINSTR (未定义指令):
- 0 = 无未定义指令
- 1 = 处理器尝试执行一条未定义指令。
- 当此位置 1 时,为异常返回而压入堆栈的 PC 值指向该未定义指令。未定义指令指处理器无法解码的指令。
潜在原因:
a) 使用了 Cortex-M 设备不支持的指令(例如 ARM 模式下的指令)。
b) 内存内容错误或损坏(例如,数据被错误地当作指令执行)。
INVSTATE (无效状态):
- 0 = 无无效状态
- 1 = 处理器尝试执行一条对 执行程序状态寄存器 (EPSR - Execution Program Status Register) 进行了非法使用的指令。
- 当此位置 1 时,为异常返回而压入堆栈的 PC 值指向那条试图非法使用 EPSR 的指令。
潜在原因:
a) 向 PC 寄存器加载了一个最低有效位 (LSB) 为 0 的分支目标地址(Cortex-M 的指令必须是半字对齐的,PC 的 LSB 应为 1)。
b) 在异常或中断处理期间,压入堆栈的 PSR 值被损坏。
c) 向量表中包含了一个 LSB 为 0 的向量地址。
INVPC (无效的 PC 加载):
- 0 = 无无效的 PC 加载
- 1 = 由于无效的 EXC_RETURN 值,处理器尝试将一个非法的 EXC_RETURN 值加载到 PC 寄存器,这通常源于一次无效的上下文切换。
- 当此位置 1 时,为异常返回而压入堆栈的 PC 值指向那条试图执行非法 PC 加载的指令。
潜在原因:
a) 由于栈指针、链接寄存器 (LR) 或栈内容损坏而导致无效返回。
b) PSR 中的 ICI/IT 位对于当前指令无效(Thumb 状态下的条件执行或中断继续指令状态不一致)。
NOCP (无协处理器):
- 0 = 无因尝试访问协处理器而引起的用法故障
- 1 = 处理器尝试访问一个不存在的协处理器。
- Cortex-M 系列通常不支持协处理器,此位用于捕获试图执行协处理器指令的行为。
UNALIGNED (未对齐访问):
0 = 无未对齐访问故障,或未使能未对齐访问陷阱
1 = 处理器进行了一次未对齐的内存访问(例如,尝试从非 4 字节对齐的地址读取一个 32 位字)。
通过设置 CCR (配置与控制寄存器) 中的 UNALIGN_TRP 位来使能未对齐访问陷阱。请注意:LDM, STM, LDRD, 和 STRD 指令的未对齐访问总是会引发故障,而与 UNALIGN_TRP 位的设置无关。
DIVBYZERO (除零错误):
- 0 = 无除零错误,或未使能除零陷阱
- 1 = 处理器执行了一条 SDIV 或 UDIV(有符号或无符号除法)指令,且除数为 0。
- 当处理器将此位置 1 时,为异常返回而压入堆栈的 PC 值指向那条执行了除零操作的指令。通过将 CCR 寄存器中的 DIV_0_TRP 位设置为 1 来使能除零陷阱。
请注意:用法故障状态寄存器中的位是粘滞 (sticky) 的。这意味着,一旦一个或多个故障发生,相关的位就会被置 1。一个被置 1 的位只能通过向该位写入 1 或通过系统复位来清零。
6.3 内存管理故障地址寄存器 (MMFAR - MemManage Fault Address Register)
MMFAR 寄存器包含了引发内存管理故障的访问操作所指向的内存地址。
ADDRESS (故障地址):该字段保存了引发内存管理故障的数据访问地址。
此寄存器会更新为产生内存管理故障的访问地址。而 MMFSR 寄存器则指明了故障的具体原因。
该字段仅在 MMFSR.MMARVALID 位被置 1 时才有效。
在那些 没有独立实现 BFAR (总线故障地址寄存器) 和 MMFAR 的处理器实现中,如果 BFSR.BFARVALID 位被置 1(表明总线故障地址有效),此寄存器的值将是未知的 (UNKNOWN)。
6.4总线故障地址寄存器 (BFAR - BusFault Address Register)
BFAR 中的地址与精确数据访问总线故障相关联。该寄存器仅允许特权访问。非特权访问将生成总线故障。
ADDRESS (故障地址):该字段保存了引发精确总线故障的数据访问地址。
此寄存器会更新为产生总线故障的访问地址。而 BFSR 寄存器则指明了故障的具体原因。该字段仅在 BFSR.BFARVALID 位被置 1 时才有效。
在那些没有独立实现 BFAR (总线故障地址寄存器) 和 MMFAR (内存管理故障地址寄存器) 的处理器实现中,如果 MMFSR.MMARVALID 位被置 1(表明内存管理故障地址有效),此寄存器的值将是未知的 (UNKNOWN)。
6.5 辅助总线故障状态寄存器 (ABFSR - Auxiliary Bus Fault Status Register) (仅 Cortex-M7)
辅助总线故障状态寄存器 (ABFSR) 存储了关于异步总线故障源的信息。如果发生了总线故障,故障处理程序可以读取此寄存器以确定是哪个总线接口触发了故障;如果故障源是 AXIM 接口,还能确定接收到的错误类型。ABFSR[4:0] 字段的值会一直保持有效,直到通过向 ABFSR 写入任意值来将其清除。ABFSR 的位定义如下:
AXIMTYPE (AXIM 接口故障类型):指示在 AXIM 接口上发生的故障类型。仅当 AXIM 位为 1 时,这些值才有效。
- 0b00 = OKAY (正常响应)
- 0b01 = EXOKAY (独占访问正常响应)
- 0b10 = SLVERR (从设备错误)
- 0b11 = DECERR (解码错误)
EPPB (EPPB 接口异步故障):指示 EPPB 接口上发生了异步故障。
AXIM (AXIM 接口异步故障):指示 AXIM 接口上发生了异步故障。
AHBP (AHBP 接口异步故障):指示 AHBP 接口上发生了异步故障。
DTCM (DTCM 接口异步故障):指示 DTCM (数据紧耦合存储器) 接口上发生了异步故障。
ITCM (ITCM 接口异步故障):指示 ITCM (指令紧耦合存储器) 接口上发生了异步故障。
注意: 上述接口在具体芯片上可能并未实现。
7 实现故障处理程序
故障处理程序可用于安全地关闭系统、向用户通报所遇到的问题,或者触发整个系统的自检。
一个符合 CMSIS 标准的启动文件(通常命名为 startup_device.s)定义了设备的所有异常和中断向量。这些向量定义了异常或中断处理函数的入口地址。
1 |
|
7.1 HardFault 处理程序示例
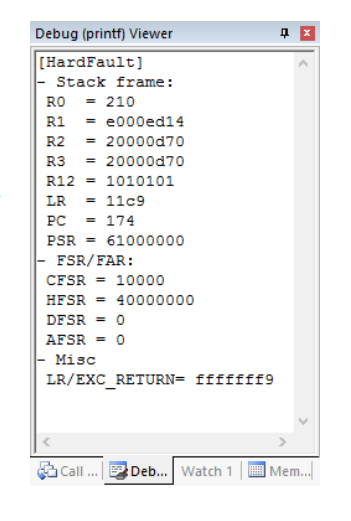
AN209_Faults_and_Handler.zip 压缩包包含了一个示例项目,其中有一个示范性的 HardFault 处理程序。该处理程序会保存内核寄存器的内容,并使用 printf 语句将其显示出来。这个自定义处理程序由两部分组成:
- 用汇编语言编写的处理程序包装器:它负责提取栈帧的位置,并将其作为一个指针传递给用 C 语言编写的处理程序。
- 用 C 语言编写的处理程序:它利用来自汇编包装器的信息来提取相关信息,并使用 printf 语句将其显示,如下图所示:
对于一个最终应用程序,可以实现一个执行以下操作的故障处理程序:
- 系统复位 (System Reset):通过设置 AIRCR (应用程序中断和复位控制寄存器) 中的位 2 (SYSRESETREQ)。这将复位系统中除调试逻辑之外的大部分部件。如果不想复位整个系统,只需设置 AIRCR 中的位 0 (VECTRESET),这将仅导致处理器内核复位。
- 恢复 (Recovery):在某些情况下,或许可以解决导致故障异常的问题。例如,对于协处理器指令,处理程序可以在软件中模拟执行该指令。
- 任务终止 (Task termination):对于运行实时操作系统 (RTOS) 的系统,可以终止引发故障的任务,并在需要时重新启动它。
7.2 ARM Cortex-M7 故障处理注意事项
1: 缓存维护操作可能导致总线故障 (BusFault)。此类故障事件是异步的(不精确的)。这种类型的总线故障:
- a. 在已启用总线故障处理程序的情况下,不会升级 (escalate) 为 HardFault。
- b. 永远不会导致系统锁定 (lockup)。
由于故障事件是异步的,执行缓存维护操作的软件代码在操作完成时必须使用内存屏障指令(如 DSB),以便能够立即观察到该故障事件。
2: Cortex-M7 中的缓存支持 ECC(错误校正码)。一旦发生不可纠正的 ECC 错误,将触发总线故障 (BusFault),软件可以通过指令错误存储库寄存器 (IEBR0-1) 和数据错误存储库寄存器 (DEBR0-1) 来管理 ECC 错误。
3: 由于总线接口的设计不同,(Cortex-M7)在总线错误行为上存在一些差异:
- a. 在 Cortex-M3 和 Cortex-M4 上,如果内存操作是向强有序 (strongly ordered) 内存区域进行写入,其产生的总线错误是精确的。而在 Cortex-M7 上,相同的操作可能触发不精确的总线错误。
- b. 在 Cortex-M3 和 Cortex-M4 上,异常序列在未完成的缓冲写入操作完成之后才开始。因此,如果发生总线错误,堆栈中保存的 PC 值与触发总线错误的代码上下文相同。在 Cortex-M7 上,异常处理序列可以在写缓冲区 (write buffer) 被清空之前就开始。在这种情况下,堆栈中保存的 PC 值可能显示不同的上下文(例如,可能在缓冲写入操作发生后不久触发了一个 IRQ 中断处理程序)。因此,在 Cortex-M7 上,如果总线故障是异步的,其处理程序不能依赖堆栈中的 PC 值来确定故障位置。
- PS: Cortex-M7 更深的Store Buffer,当Store Buffer中的写入操作失败时,错误报告会延迟,此时CPU的上下文(如PC值)可能已经改变。
8 使用 µVision® 调试故障
该示例项目 (www.keil.com/appnotes/docs/apnt_209.asp) 演示了三种不同的故障异常:
- 调用一条不属于 ARM 指令集的指令,将导致 未定义指令用法故障 (UNDEFINSTR)。
- 跳转到一个有效但未设置 Thumb 位的内存地址,将导致 无效状态用法故障 (INVSTATE)。
- 任何数字除以零的操作,将触发 除零用法故障 (DIVBYZERO)。
1 | volatile int i, j = 0; // Variables for the division-by-zero |
8.1 从“外设”菜单访问故障报告对话框
ARM Cortex-M 故障寄存器会准确指示发生了哪种异常。µVision 在 “外设 (Peripherals)” –> “内核外设 (Core Peripherals)” 菜单下的 “故障报告 (Fault Reports)” 对话框中提供了所有故障寄存器的当前值。
该故障报告对话框提供了已发生异常的详细信息。在此案例中(软件包示例项目中的 TESTCASE INVSTATE),是一次尝试切换到无效状态(ARM 状态) 的操作导致了用法故障 (UsageFault);并且由于用法故障处理程序未启用,该故障被升级 (escalated) 为了硬故障 (HardFault)。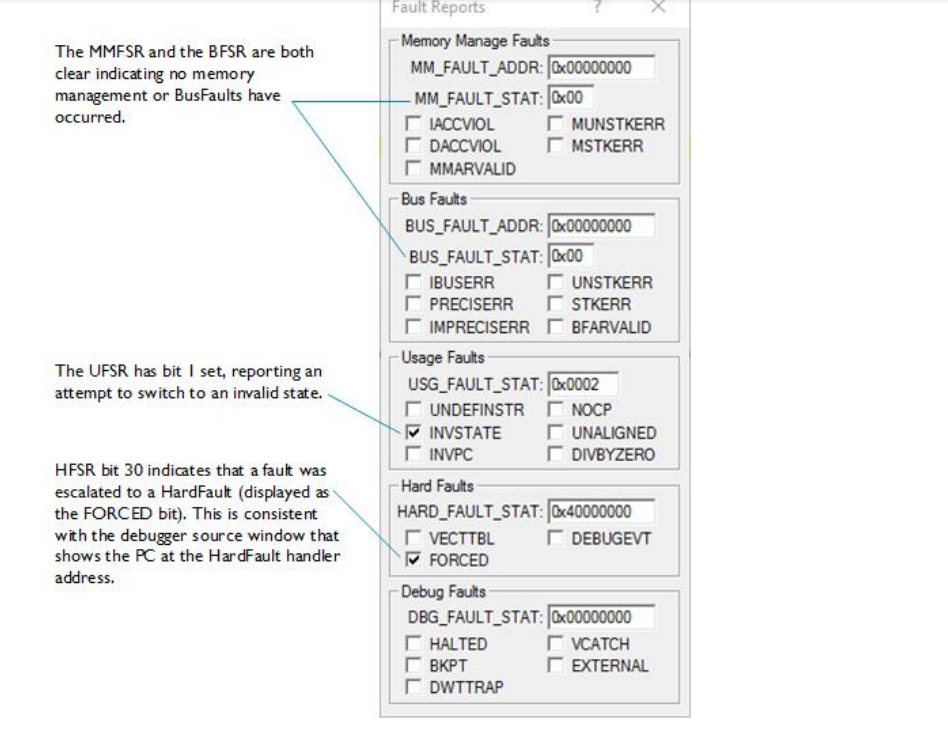
此故障报告对话框是分析故障异常的快捷途径。如果您的调试器不支持此类对话框,则可以通过内存窗口 (memory window) 来查看这些寄存器的值。
8.2 确定异常发生的位置
异常发生时,硬件自动压栈,异常栈帧结构如下: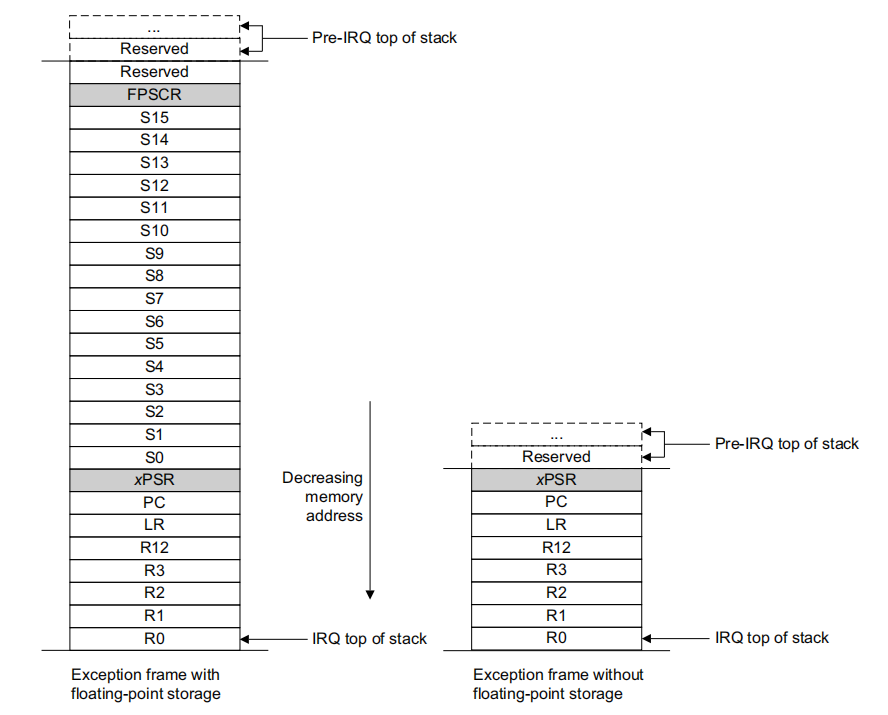
在示例项目中,使能 DIVBYZERO (除零) 用法故障,然后运行应用程序直至其最终进入 HardFault。
在 “调用堆栈 + 局部变量 (Call Stack + Locals)”窗口中,右键单击 HardFault_Handler,然后选择 “查看调用者代码 (Show Caller Code)”,以高亮显示异常发生时的执行上下文: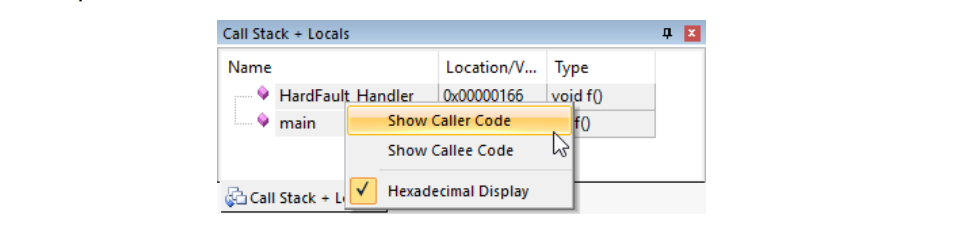
根据异常类型的不同,调试器会高亮显示导致异常的指令,或者导致故障的指令的下一条指令。这取决于导致异常的指令是否实际上已经执行完成。
在 main.c 中,以下行被高亮显示:
i =i/j; // i and j are 0 initialized -> Div/0
发生异常时,会保存寄存器 R0-R3, R12, PC 和 LR 的状态,以及 MSP 或 PSP 的值(具体取决于异常发生时正在使用的堆栈)。当前的链接寄存器 LR 包含正在处理的异常的 EXC_RETURN 值,该值指示了哪个堆栈保存着来自应用程序上下文的寄存器值。如果 EXC_RETURN 的位 2 为 0,则表示使用的是主堆栈(MSP 被保存),否则使用的是进程堆栈(PSP 被保存)。寄存器 (Registers) 窗口提供了所需的信息: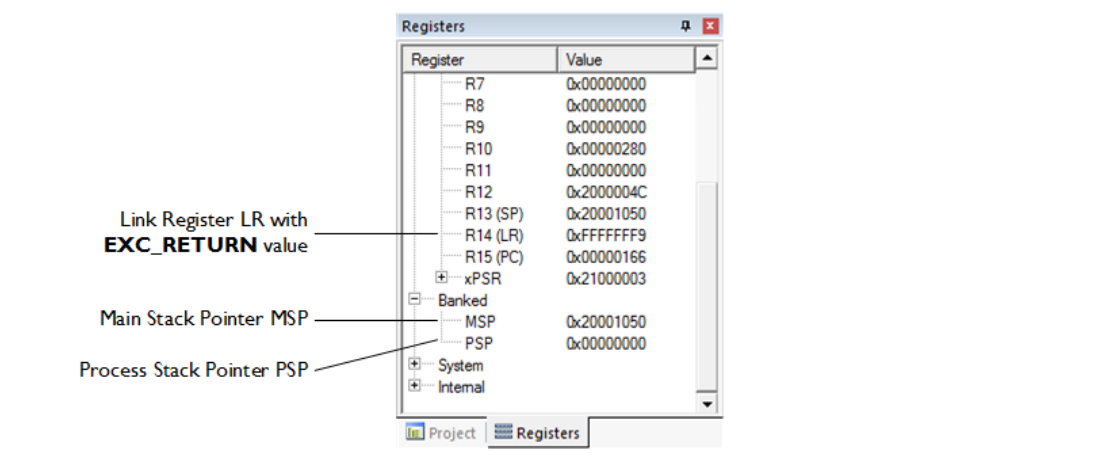
在此示例中,EXC_RETURN 的值为:
0xfffffff9 = b_11111111111111111111111111111001 – 位 2 = 0
这表示主堆栈 (MSP) 包含了最近存储的寄存器值。MSP 和 PSP 的地址在此处也可见。
MSP 指向 0x20001050。可以使用内存窗口 (Memory Window) 来查看先前的执行上下文: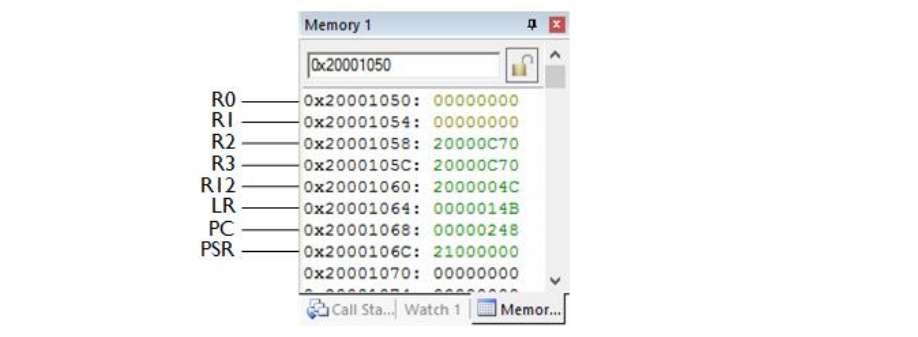
这对应于我们之前在调试器中看到的信息:
- PC = 0x00000249: 即将导致用法故障的下一条指令(此处为:SDIV 指令之后)。
- R0-R3 & R12: 这些是异常发生前寄存器中的值。
通过利用来自故障状态寄存器的详细信息以及相应的堆栈,调试器提供了发现发生了何种异常以及异常发生位置所需的信息。要进一步调试此特定问题(除零),必须复位系统,并在被破坏的函数指针上设置观察点 (watch point)。这将揭示问题的根本原因。
参考连接:
【1】APNT209.pdf