cache coherence
关于CPU cache的基础介绍,参考文章:cpu cace
1 什么是 cache coherence:
缓存一致性问题是一个通用概念,当系统中多个访问数据的客户端均对某些公享数据进行缓存时,各个客户端的缓存数据间就可能出现不一致的问题。如下图所示:
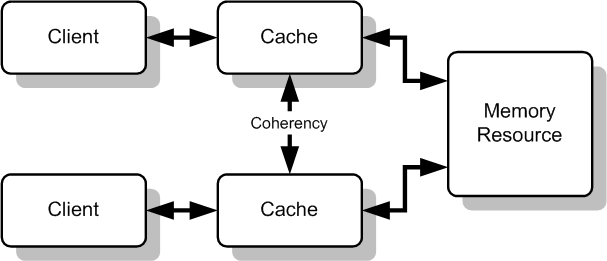
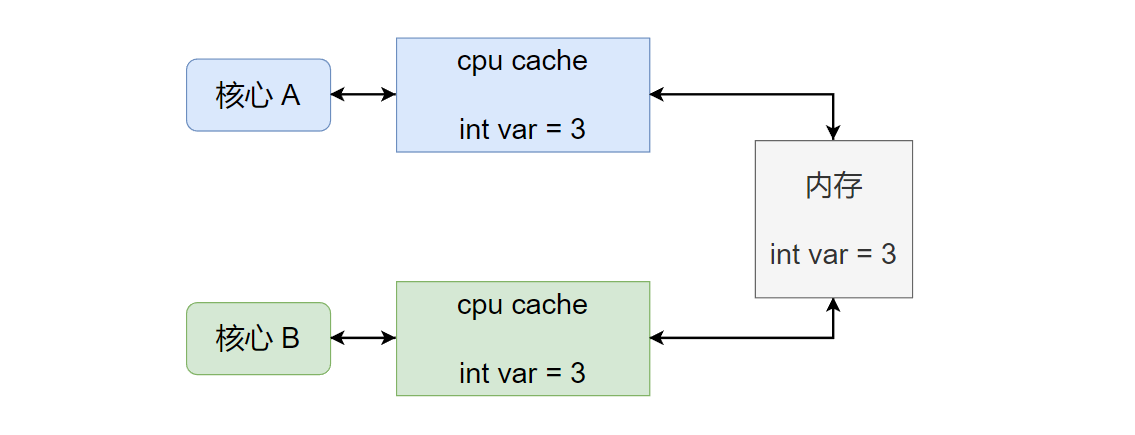
现代cpu往往都是多核心的,每个核心可以看做上图的client,每个核心都有自己独立的cpu cache(L1、L2 cache)。当某个时刻核心 A和核心 B均访问内存中的某个数据var时,每个核心会将var加载到自己的 cpu cache中,如下图所示:
此时,如果核心A修改变量var的值,会直接修改自己 cache中缓存的值。那么,核心A和核心B的cache中缓存的var就会不一致(并且核心Acache中的更新的var不一定会立刻写回内存中,例如使用了write-back写回策略)。如下图所示: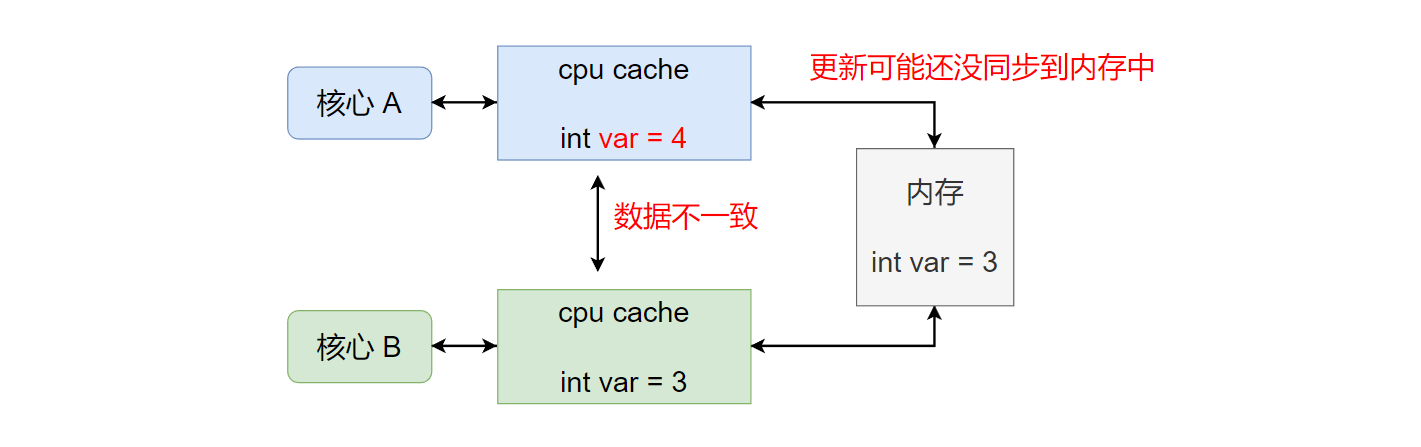
进一步,由于核心A的更新操作可能还没同步到内存中,如果此时另一个核心C也开始读取变量var(第一次读取),核心C会将var从内存加载到自己的 cpu cache中,那么此时读取到的就是var的旧值,并不是核心A更新后的最新的值。如下图所示: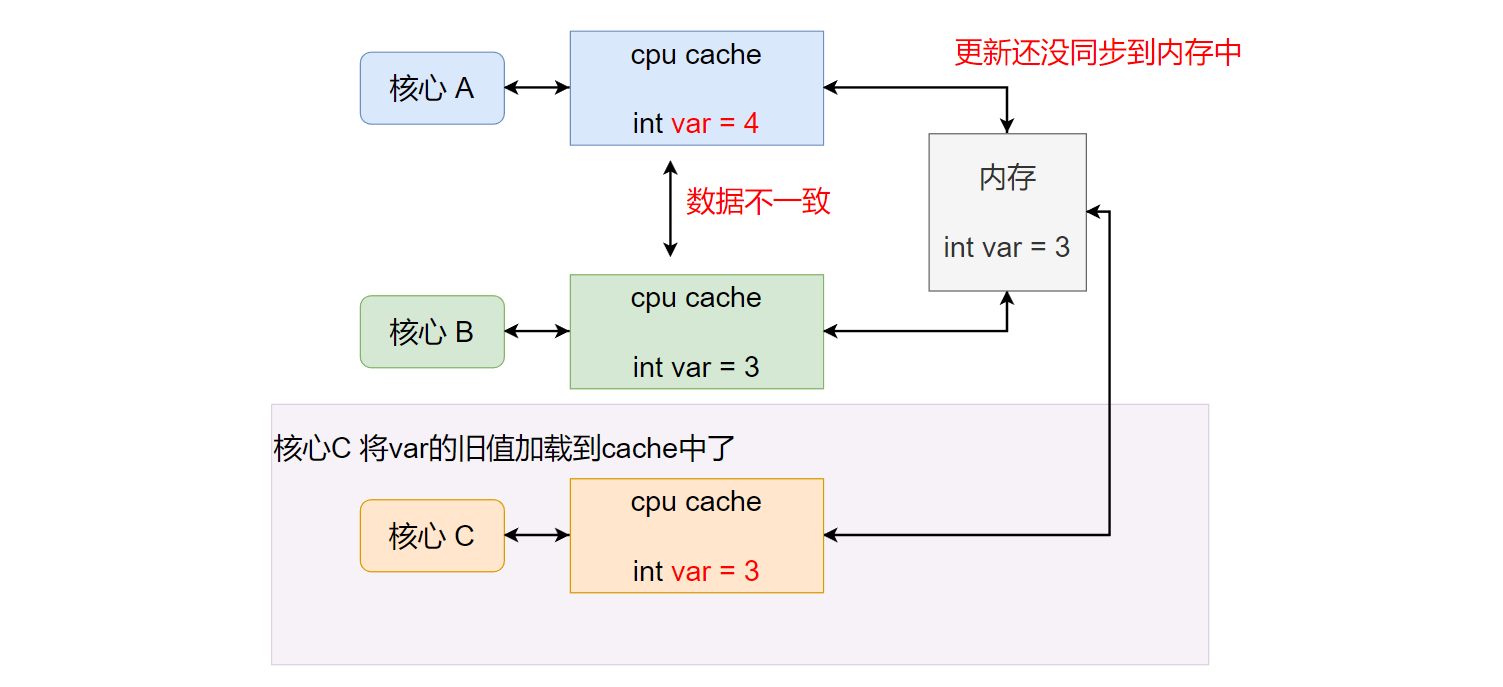
上述问题,就是由于共享数据在多处存在独立的缓存,从而造成缓存数据不一致问题。
而缓存一致性(cache coherence)就是是确保共享数据值的变化,在整个系统中及时传播的,使得某个cache中的数据发生更改时,其他也包含该数据的cache能及时感知该更改。
2 缓存一致性需要满足的基本要求
为了实现缓存一致性,首先需要满足下面两个要求:
- 写传播(write propagation):对任何缓存中的某个数据的更改,必须传播给该数据所在的其它所有缓存。
- 事务串行化(Transaction Serialization):对某个内存位置的多个读/写操作(例如两个写操作:
核心A写,之后核心B写),所有处理器核心应该看到相同的操作循序(所有处理器看到的写操作顺序,应该都是核心A写,之后核心B写)。
2.1 写传播(Write Propagation)
在核心A对var 的写操作之后,核心B对var进行读操作,并且在两次访问之间没有其它核心对var的写操作,那么核心B对var的读必须总是返回核心A所写的值。
这个要求是在抽象逻辑层面上,对最终结果的要求(CPU内部可能为了获得最终结果,需要做额外的其它操作):核心A更新了var的值之后,核心B读取var的值应该读取到核心A更新后的值(两个操作间无其它核心对var的写操作)。即对某一个缓存中的某个数据的更改操作,必须传播到该数据所在的所有缓存中。如下图所示: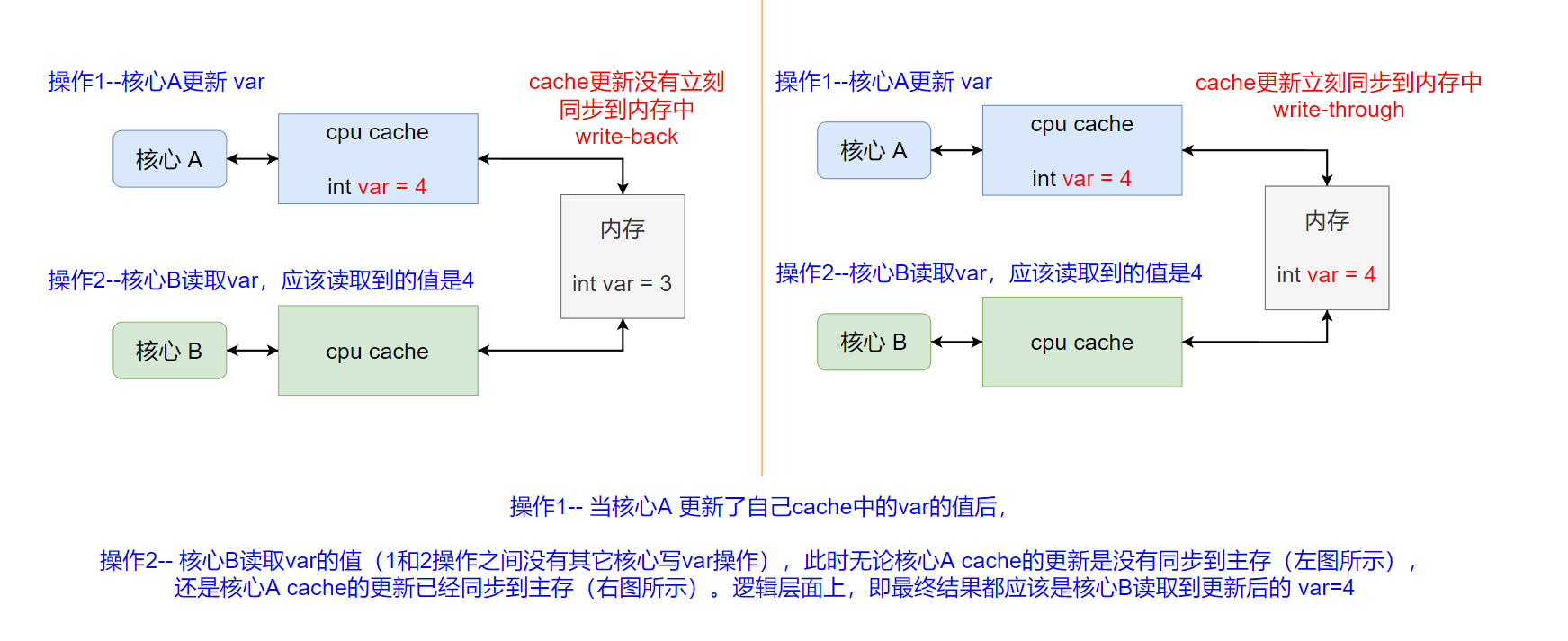
操作1的写 和 操作2的读 指的是指令级别操作,要使得最终核心B 读取的结果是核心A更新后值,在操作1和操作2之间肯定还需要处理器进行cache间的信息同步操作(上图的例子,就是需要将核心A的cache的写操作的同步给核心B的cache),之后处理器根据数据的状态,来决定核心B怎么读取数据var。例如,当核心A使用的write-back策略时(核心A的cache更新没有立刻同步回主存),核心B的读操作会触发核心A将自己cache中的更新数据通过总线同时同步给核心B的cache以及主存。之后核心B就可以返回更新后的var=4了,如下图所示: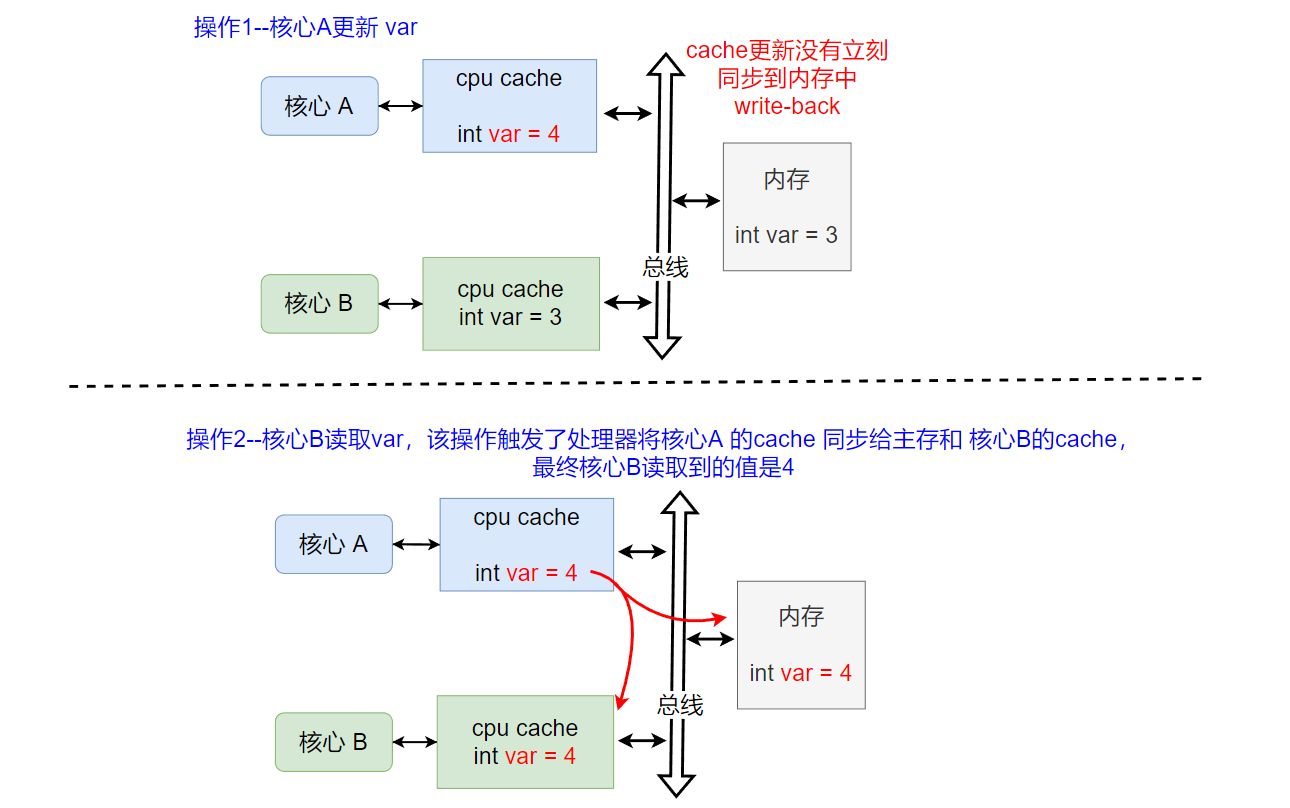
2.2 事务串行化(Transaction Serialization)
写传播(Write Propagation)是针对单次更新的要求,即一次对CPU cache的更新操作,应该传播给包含该更新数据的所有cpu cache。但仅保证写传播,不足以实现缓存一致性。
考虑 核心A和核心B都对同一和变量更新值,那么核心C和核心D如果看到更新顺序不一致,还是会导致缓存间数据不一致问题,一个wikipedia中的例子如下:
核心A、B、C和D,各自的cpu cache中都包含共享变量var的缓存副本。核心A将var的值(在它自己的cache中)更改为10,
随后,核心B将var的值(在它自己的cache中)更改为20。
如果只保证写传播(write propagation),那么核心C和核心D可以保证都能看到核心A和核心B对var所做的更改。
但是,核心C可能是先看到核心B的更改操作,之后再看到核心A的更改操作,因此核心C在之后的读取返回10。
而核心D可能是先看到核心A的更改操作,之后在看到核心B的更改操作,因此核心D在之后的读取返回20。
即,仅保证写传播,仍旧会导致cache间的数据不一致问题,如下图所示:下图重点是核心C、D感知核心A、B两个写操作的顺序(图中没画核心A/B感知B/A的更新)![]()
因此,事务(操作)串行化也是实现缓存一致性的必要要求。
实现事务串行化,就需要对同一位置的写入操作必须进行排序(串行化,将写入顺序固定,这样所有其它核心看到的写入操作顺序都是一致的)。
对某个内存位置 X 的多个写操作(上图的核心A写10,之后核心B写20),所有处理器核心应该看到相同的写顺序(例如,所有核心看到的树顺序都是位置 X 先被写10,之后被写20),不能出现某个核心C能从位置 X 先读出 20,然后又读出 10 的情况(即核心C先看到了写20,后看到写10)。
3 一致性机制(Coherence mechanisms)
一致性机制,是CPU为了实现缓存一致性而提供的基本硬件机制。两种常见的机制有基于总线嗅探(Bus snooping)的机制和基于目录(Directory-based)的机制。
3.1 基于总线嗅探机制
每个核心对自己cpu cache操作,会传播到总线上。同时,每个核心的cpu cache会监听总线,如下图所示: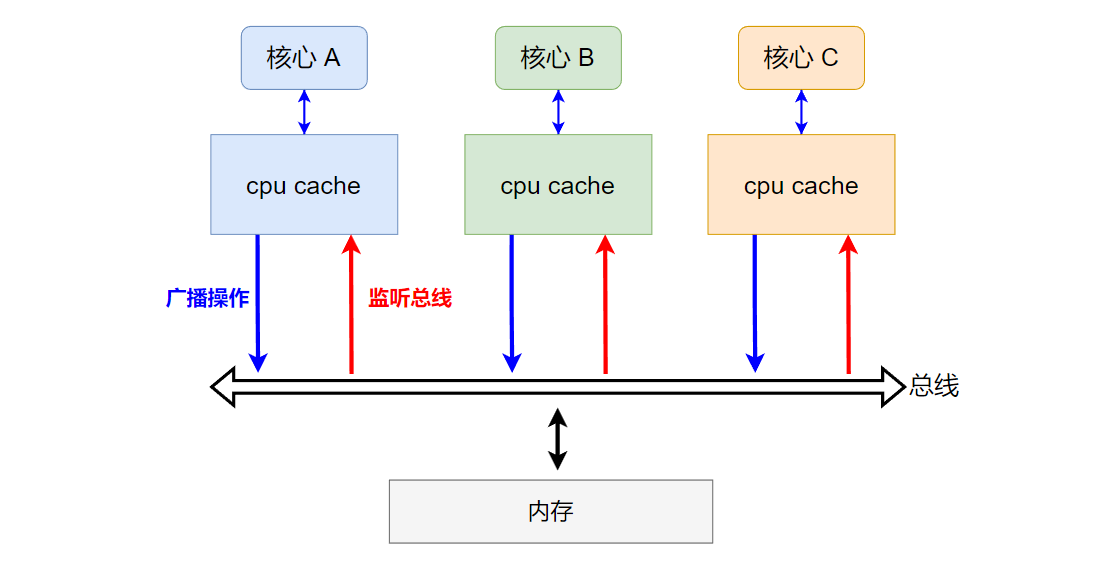
当监听到修改操作时,会判断当前修改的数据是否也在自己的cpu cache中,如果在则依据采用的缓存一致性协议执行对应的动作,例如让自己的cpu cache中相应的数据变为无效(当数据在其它核心的cpu cache中被更新时)。
3.2 基于目录机制
在基于目录的系统中,共享数据的所在位置和状态被放在一个公共目录中,数据在哪几个核心的cpu cache中存在副本,可以通过该目录查找。如下图所示:
其中,Nodes中对应的位为1,表示对应核心的cpu cache中存在该数据。 Location表示该数据在内存中的位置,访问数据就是访问内存中的某个位置。
状态标记分别为:E=Exclusive, S=Shared, M=Modified, and U=Uncached
P1、P2、P3 看做CPU中的多个核心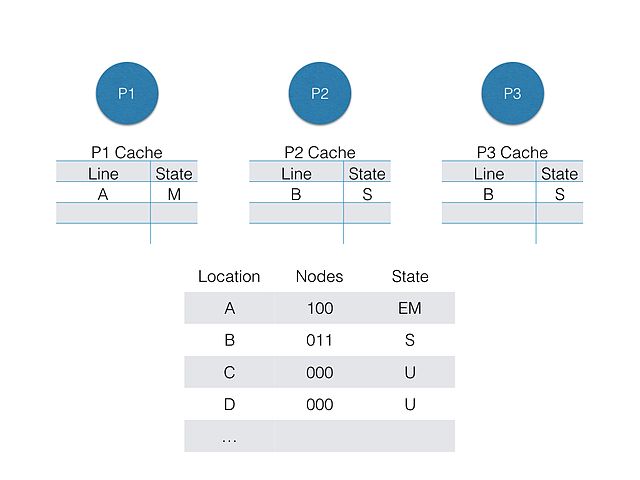
因此,该机制会多一个目录查找过程。但另一方面对数据的修改操作可以直接通过该目录知道会影响哪几个核心的cpu cache,而基于总线,由于不清楚会影响哪几个核心的cpu cache,因此操作都要广播到总线上,让其它核心去检测是否与自己cpu cache中的数据有关。
总结
总线嗅探机制 或 基于目录的机制,是实现缓存一致性的硬件基础。基于该基础,还需要提出一套具体的协议规范,来满足写传播和事务串行化要求,从而最终实现多个缓存间数据的一直性。例如 MESI协议,就是基于总线嗅探实现的缓存一致性协议。
参考资料:
【1】https://en.wikipedia.org/wiki/Cache_coherence
【2】https://en.wikipedia.org/wiki/MESI_protocol
【3】https://en.wikipedia.org/wiki/Directory-based_cache_coherence
【4】https://en.wikipedia.org/wiki/Bus_snooping
【5】https://xiaolincoding.com/os/1_hardware/cpu_mesi.html